3 min of Machine Learning: Cross Vaildation
Goal
Only use numpy to develop code for my_ cross_ val(method,X,y,k), which performs k-fold crossvalidation
on (X; y) using method, and returns the error rate in each fold. Using
this own written cross cilidation function to report the error rates in each fold as well as the mean and standard deviation
of error rates across folds for the different methods.In the end, to compare its performance with the default sklearn
Why Cross Validation
The goal for doing Cross-Validation is to estimate generalization error. We need data unseen during training. Sometimes, the size of sample isn’t large, we need to resample. Hence, we need to use Cross Validation
Algorithm
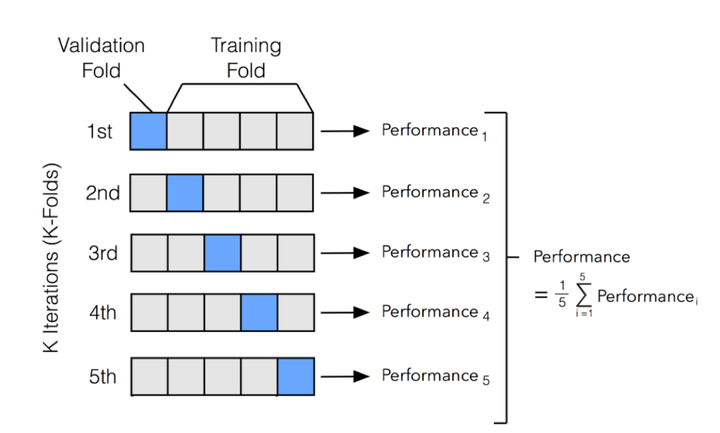
The general procedure is as follows:
1.Shuffle the dataset randomly.
2.Split the dataset into k groups
3.For each unique group:
a. Take the group as a hold out or test data set
b. Take the remaining groups as a training data set
c.Fit a model on the training set and evaluate it on the test set
d.Retain the evaluation score and discard the model
4.Summarize the skill of the model using the sample of model evaluation scores
Python Code
Performance
The default model is cross_val_score from sklearn.
I test on the datasets: digits , which is from sklearn, with model logistic regression, SVC, and linearSVC.
Here is the result for the mean of error rate in percent when k = 10.
| Command | Logistic Regression | SVC | Linear SVC |
|---|---|---|---|
| My Own CV | 3.50 | 1.11 | 5.23 |
| sklearn CV | 7.20 | 1.83 | 8.62 |